第 18 章 离线强化学习
18.1 简介
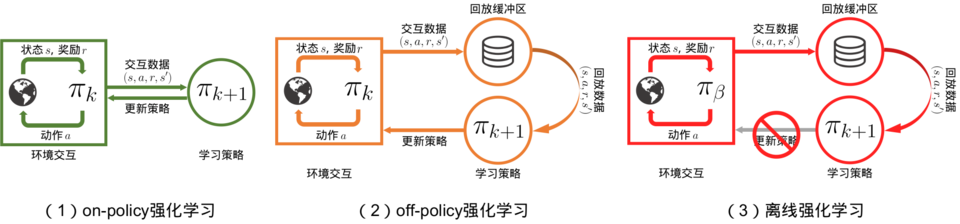
在前面的学习中,我们已经对强化学习有了不少了解。无论是在线策略(on-policy)算法还是离线策略(off-policy)算法,都有一个共同点:智能体在训练过程中可以不断和环境交互,得到新的反馈数据。二者的区别主要在于在线策略算法会直接使用这些反馈数据,而离线策略算法会先将数据存入经验回放池中,需要时再采样。然而,在现实生活中的许多场景下,让尚未学习好的智能体和环境交互可能会导致危险发生,或是造成巨大损失。例如,在训练自动驾驶的规控智能体时,如果让智能体从零开始和真实环境进行交互,那么在训练的最初阶段,它操控的汽车无疑会横冲直撞,造成各种事故。再例如,在推荐系统中,用户的反馈往往比较滞后,统计智能体策略的回报需要很长时间。而如果策略存在问题,早期的用户体验不佳,就会导致用户流失等后果。因此,离线强化学习(offline reinforcement learning)的目标是,在智能体不和环境交互的情况下,仅从已经收集好的确定的数据集中,通过强化学习算法得到比较好的策略。离线强化学习和在线策略算法、离线策略算法的区别如图 18-1 所示。
18.2 批量限制 Q-learning 算法
图 18-1 中的离线强化学习和离线策略强化学习很像,都要从经验回放池中采样进行训练,并且离线策略算法的策略评估方式也多种多样。因此,研究者们最开始尝试将离线策略算法直接照搬到离线的环境下,仅仅是去掉算法中和环境交互的部分。然而,这种做法完全失败了。研究者进行了 3 个简单的实验。第一个实验,作者使用 DDPG 算法训练了一个智能体,并将智能体与环境交互的所有数据都记录下来,再用这些数据训练离线 DDPG 智能体。第二个实验,在线 DDPG 算法在训练时每次从经验回放池中采样,并用相同的数据同步训练离线 DDPG 智能体,这样两个智能体甚至连训练时用到的数据顺序都完全相同。第三个实验,在线 DDPG 算法在训练完毕后作为专家,在环境中采集大量数据,供离线 DDPG 智能体学习。这 3 个实验,即完全回放、同步训练、模仿训练的结果依次如图 18-2 所示。
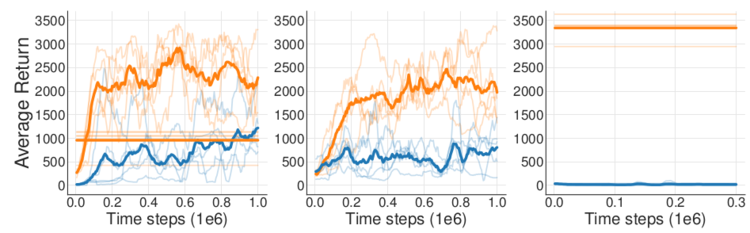
让人惊讶的是,3 个实验中,离线 DDPG 智能体的表现都远远差于在线 DDPG 智能体,即便是第二个实验的同步训练都无法提高离线智能体的表现。在第三个模仿训练实验中,离线智能体面对非常优秀的数据样本却什么都没学到!针对这种情况,研究者指出,外推误差(extrapolation error)是离线策略算法不能直接迁移到离线环境中的原因。
外推误差,是指由于当前策略可能访问到的状态动作对与从数据集中采样得到的状态动作对的分布不匹配而产生的误差。为什么在线强化学习算法没有受到外推误差的影响呢?因为对于在线强化学习,即使训练是离线策略的,智能体依然有机会通过与环境交互及时采样到新的数据,从而修正这些误差。但是在离线强化学习中,智能体无法和环境交互。因此,一般来说,离线强化学习算法要想办法尽可能地限制外推误差的大小,从而得到较好的策略。
为了减少外推误差,当前的策略需要做到只访问与数据集中相似的
- 最小化选择的动作与数据集中数据的距离;
- 采取动作后能到达与离线数据集中状态相似的状态;
- 最大化函数
。
对于标准的表格(tabular)型环境,状态和动作空间都是离散且有限的。标准的 Q-learning 更新公式可以写为:
这时,只需要把策略
可以证明,如果数据中包含了所有可能的
连续状态和动作的情况要复杂一些,因为批量限制策略的目标需要被更详细地定义。例如,该如何定义两个状态动作对的距离呢?BCQ 采用了一种巧妙的方法:训练一个生成模型
其中,生成模型
总结起来,BCQ 算法的流程如下:
- 随机初始化
网络 、扰动网络 、生成网络 - 用
初始化目标 网络 ,用 初始化目标扰动网络 - for 训练次数
do 从数据集 中采样一定数量的 编码器生成均值和标准差 解码器生成动作 ,其中 更新生成模型: 从生成模型中采样 个动作: 对每个动作施加扰动: 计算 网络的目标值 更新 网络: 更新扰动网络: 更新目标 网络: 更新目标扰动网络: - end for
除此之外,BCQ 还使用了一些实现上的小技巧。由于不是 BCQ 的重点,此处不再赘述。考虑到 VAE 不属于本书的讨论范围,并且 BCQ 的代码中有较多技巧,有兴趣的读者可以参阅 BCQ 原文,自行实现代码。此处介绍 BCQ 算法,一是因为它对离线强化学习的误差分析和实验很有启发性,二是因为它是无模型离线强化学习中限制策略集合算法中的经典方法。下面我们介绍另一类直接限制函数
18.3 保守 Q-learning 算法
18.2 节已经讲到,离线强化学习面对的巨大挑战是如何减少外推误差。实验证明,外推误差主要会导致在远离数据集的点上函数
在普通的 Q-learning 中,
其中,
其中,
将行为策略
至此,CQL 算法已经有了理论上的保证,但仍有一个缺陷:计算的时间开销太大了。当令
为了防止过拟合,再加上正则项
正则项采用和一个先验策略
可以注意到,简化后式中已经不含有
上面给出了函数
总结起来,CQL 算法流程如下:
- 初始化
网络 、目标 网络 和策略 、熵正则系数 - for 训练次数
do 更新熵正则系数: 更新函数 : 更新策略: - end for
18.4 CQL 代码实践
下面在倒立摆环境中实现基础的 CQL 算法。该环境在前面的章节中已出现了多次,这里不再重复介绍。首先导入必要的库。
import numpy as npimport gymfrom tqdm import tqdmimport randomimport rl_utilsimport torchimport torch.nn as nnimport torch.nn.functional as Ffrom torch.distributions import Normalimport matplotlib.pyplot as plt
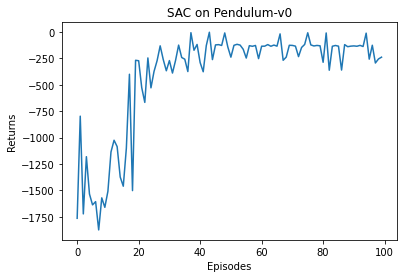
为了生成数据集,在倒立摆环境中从零开始训练一个在线 SAC 智能体,直到算法达到收敛效果,把训练过程中智能体采集的所有轨迹保存下来作为数据集。这样,数据集中既包含训练初期较差策略的采样,又包含训练后期较好策略的采样,是一个混合数据集。下面给出生成数据集的代码,SAC 部分直接使用 14.5 节中的代码,因此不再详细解释。
class PolicyNetContinuous(torch.nn.Module):def __init__(self, state_dim, hidden_dim, action_dim, action_bound):super(PolicyNetContinuous, self).__init__()self.fc1 = torch.nn.Linear(state_dim, hidden_dim)self.fc_mu = torch.nn.Linear(hidden_dim, action_dim)self.fc_std = torch.nn.Linear(hidden_dim, action_dim)self.action_bound = action_bounddef forward(self, x):x = F.relu(self.fc1(x))mu = self.fc_mu(x)std = F.softplus(self.fc_std(x))dist = Normal(mu, std)normal_sample = dist.rsample() # rsample()是重参数化采样log_prob = dist.log_prob(normal_sample)action = torch.tanh(normal_sample)# 计算tanh_normal分布的对数概率密度log_prob = log_prob - torch.log(1 - torch.tanh(action).pow(2) + 1e-7)action = action * self.action_boundreturn action, log_probclass QValueNetContinuous(torch.nn.Module):def __init__(self, state_dim, hidden_dim, action_dim):super(QValueNetContinuous, self).__init__()self.fc1 = torch.nn.Linear(state_dim + action_dim, hidden_dim)self.fc2 = torch.nn.Linear(hidden_dim, hidden_dim)self.fc_out = torch.nn.Linear(hidden_dim, 1)def forward(self, x, a):cat = torch.cat([x, a], dim=1)x = F.relu(self.fc1(cat))x = F.relu(self.fc2(x))return self.fc_out(x)class SACContinuous:''' 处理连续动作的SAC算法 '''def __init__(self, state_dim, hidden_dim, action_dim, action_bound,actor_lr, critic_lr, alpha_lr, target_entropy, tau, gamma,device):self.actor = PolicyNetContinuous(state_dim, hidden_dim, action_dim,action_bound).to(device) # 策略网络self.critic_1 = QValueNetContinuous(state_dim, hidden_dim,action_dim).to(device) # 第一个Q网络self.critic_2 = QValueNetContinuous(state_dim, hidden_dim,action_dim).to(device) # 第二个Q网络self.target_critic_1 = QValueNetContinuous(state_dim,hidden_dim, action_dim).to(device) # 第一个目标Q网络self.target_critic_2 = QValueNetContinuous(state_dim,hidden_dim, action_dim).to(device) # 第二个目标Q网络# 令目标Q网络的初始参数和Q网络一样self.target_critic_1.load_state_dict(self.critic_1.state_dict())self.target_critic_2.load_state_dict(self.critic_2.state_dict())self.actor_optimizer = torch.optim.Adam(self.actor.parameters(),lr=actor_lr)self.critic_1_optimizer = torch.optim.Adam(self.critic_1.parameters(),lr=critic_lr)self.critic_2_optimizer = torch.optim.Adam(self.critic_2.parameters(),lr=critic_lr)# 使用alpha的log值,可以使训练结果比较稳定self.log_alpha = torch.tensor(np.log(0.01), dtype=torch.float)self.log_alpha.requires_grad = True #对alpha求梯度self.log_alpha_optimizer = torch.optim.Adam([self.log_alpha],lr=alpha_lr)self.target_entropy = target_entropy # 目标熵的大小self.gamma = gammaself.tau = tauself.device = devicedef take_action(self, state):state = torch.tensor([state], dtype=torch.float).to(self.device)action = self.actor(state)[0]return [action.item()]def calc_target(self, rewards, next_states, dones): # 计算目标Q值next_actions, log_prob = self.actor(next_states)entropy = -log_probq1_value = self.target_critic_1(next_states, next_actions)q2_value = self.target_critic_2(next_states, next_actions)next_value = torch.min(q1_value,q2_value) + self.log_alpha.exp() * entropytd_target = rewards + self.gamma * next_value * (1 - dones)return td_targetdef soft_update(self, net, target_net):for param_target, param in zip(target_net.parameters(),net.parameters()):param_target.data.copy_(param_target.data * (1.0 - self.tau) +param.data * self.tau)def update(self, transition_dict):states = torch.tensor(transition_dict['states'],dtype=torch.float).to(self.device)actions = torch.tensor(transition_dict['actions'],dtype=torch.float).view(-1, 1).to(self.device)rewards = torch.tensor(transition_dict['rewards'],dtype=torch.float).view(-1, 1).to(self.device)next_states = torch.tensor(transition_dict['next_states'],dtype=torch.float).to(self.device)dones = torch.tensor(transition_dict['dones'],dtype=torch.float).view(-1, 1).to(self.device)rewards = (rewards + 8.0) / 8.0 # 对倒立摆环境的奖励进行重塑# 更新两个Q网络td_target = self.calc_target(rewards, next_states, dones)critic_1_loss = torch.mean(F.mse_loss(self.critic_1(states, actions), td_target.detach()))critic_2_loss = torch.mean(F.mse_loss(self.critic_2(states, actions), td_target.detach()))self.critic_1_optimizer.zero_grad()critic_1_loss.backward()self.critic_1_optimizer.step()self.critic_2_optimizer.zero_grad()critic_2_loss.backward()self.critic_2_optimizer.step()# 更新策略网络new_actions, log_prob = self.actor(states)entropy = -log_probq1_value = self.critic_1(states, new_actions)q2_value = self.critic_2(states, new_actions)actor_loss = torch.mean(-self.log_alpha.exp() * entropy -torch.min(q1_value, q2_value))self.actor_optimizer.zero_grad()actor_loss.backward()self.actor_optimizer.step()# 更新alpha值alpha_loss = torch.mean((entropy - self.target_entropy).detach() * self.log_alpha.exp())self.log_alpha_optimizer.zero_grad()alpha_loss.backward()self.log_alpha_optimizer.step()self.soft_update(self.critic_1, self.target_critic_1)self.soft_update(self.critic_2, self.target_critic_2)env_name = 'Pendulum-v0'env = gym.make(env_name)state_dim = env.observation_space.shape[0]action_dim = env.action_space.shape[0]action_bound = env.action_space.high[0] # 动作最大值random.seed(0)np.random.seed(0)env.seed(0)torch.manual_seed(0)actor_lr = 3e-4critic_lr = 3e-3alpha_lr = 3e-4num_episodes = 100hidden_dim = 128gamma = 0.99tau = 0.005 # 软更新参数buffer_size = 100000minimal_size = 1000batch_size = 64target_entropy = -env.action_space.shape[0]device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")replay_buffer = rl_utils.ReplayBuffer(buffer_size)agent = SACContinuous(state_dim, hidden_dim, action_dim, action_bound,actor_lr, critic_lr, alpha_lr, target_entropy, tau,gamma, device)return_list = rl_utils.train_off_policy_agent(env, agent, num_episodes,replay_buffer, minimal_size,batch_size)
Iteration 0: 0%| | 0/10 [00:00<?, ?it/s]/usr/local/lib/python3.7/dist-packages/ipykernel_launcher.py:61: UserWarning: Creating a tensor from a list of numpy.ndarrays is extremely slow. Please consider converting the list to a single numpy.ndarray with numpy.array() before converting to a tensor. (Triggered internally at ../torch/csrc/utils/tensor_new.cpp:201.)Iteration 0: 100%|██████████| 10/10 [00:08<00:00, 1.23it/s, episode=10, return=-1534.655]Iteration 1: 100%|██████████| 10/10 [00:15<00:00, 1.52s/it, episode=20, return=-1085.715]Iteration 2: 100%|██████████| 10/10 [00:15<00:00, 1.53s/it, episode=30, return=-364.507]Iteration 3: 100%|██████████| 10/10 [00:15<00:00, 1.53s/it, episode=40, return=-222.485]Iteration 4: 100%|██████████| 10/10 [00:15<00:00, 1.58s/it, episode=50, return=-157.978]Iteration 5: 100%|██████████| 10/10 [00:15<00:00, 1.55s/it, episode=60, return=-166.056]Iteration 6: 100%|██████████| 10/10 [00:15<00:00, 1.55s/it, episode=70, return=-143.147]Iteration 7: 100%|██████████| 10/10 [00:15<00:00, 1.57s/it, episode=80, return=-127.939]Iteration 8: 100%|██████████| 10/10 [00:15<00:00, 1.55s/it, episode=90, return=-180.905]Iteration 9: 100%|██████████| 10/10 [00:15<00:00, 1.53s/it, episode=100, return=-171.265]
episodes_list = list(range(len(return_list)))plt.plot(episodes_list, return_list)plt.xlabel('Episodes')plt.ylabel('Returns')plt.title('SAC on {}'.format(env_name))plt.show()
下面实现本章重点讨论的 CQL 算法,它在 SAC 的代码基础上做了修改。
class CQL:''' CQL算法 '''def __init__(self, state_dim, hidden_dim, action_dim, action_bound,actor_lr, critic_lr, alpha_lr, target_entropy, tau, gamma,device, beta, num_random):self.actor = PolicyNetContinuous(state_dim, hidden_dim, action_dim,action_bound).to(device)self.critic_1 = QValueNetContinuous(state_dim, hidden_dim,action_dim).to(device)self.critic_2 = QValueNetContinuous(state_dim, hidden_dim,action_dim).to(device)self.target_critic_1 = QValueNetContinuous(state_dim, hidden_dim,action_dim).to(device)self.target_critic_2 = QValueNetContinuous(state_dim, hidden_dim,action_dim).to(device)self.target_critic_1.load_state_dict(self.critic_1.state_dict())self.target_critic_2.load_state_dict(self.critic_2.state_dict())self.actor_optimizer = torch.optim.Adam(self.actor.parameters(),lr=actor_lr)self.critic_1_optimizer = torch.optim.Adam(self.critic_1.parameters(),lr=critic_lr)self.critic_2_optimizer = torch.optim.Adam(self.critic_2.parameters(),lr=critic_lr)self.log_alpha = torch.tensor(np.log(0.01), dtype=torch.float)self.log_alpha.requires_grad = True #对alpha求梯度self.log_alpha_optimizer = torch.optim.Adam([self.log_alpha],lr=alpha_lr)self.target_entropy = target_entropy # 目标熵的大小self.gamma = gammaself.tau = tauself.beta = beta # CQL损失函数中的系数self.num_random = num_random # CQL中的动作采样数def take_action(self, state):state = torch.tensor([state], dtype=torch.float).to(device)action = self.actor(state)[0]return [action.item()]def soft_update(self, net, target_net):for param_target, param in zip(target_net.parameters(),net.parameters()):param_target.data.copy_(param_target.data * (1.0 - self.tau) +param.data * self.tau)def update(self, transition_dict):states = torch.tensor(transition_dict['states'],dtype=torch.float).to(device)actions = torch.tensor(transition_dict['actions'],dtype=torch.float).view(-1, 1).to(device)rewards = torch.tensor(transition_dict['rewards'],dtype=torch.float).view(-1, 1).to(device)next_states = torch.tensor(transition_dict['next_states'],dtype=torch.float).to(device)dones = torch.tensor(transition_dict['dones'],dtype=torch.float).view(-1, 1).to(device)rewards = (rewards + 8.0) / 8.0 # 对倒立摆环境的奖励进行重塑next_actions, log_prob = self.actor(next_states)entropy = -log_probq1_value = self.target_critic_1(next_states, next_actions)q2_value = self.target_critic_2(next_states, next_actions)next_value = torch.min(q1_value,q2_value) + self.log_alpha.exp() * entropytd_target = rewards + self.gamma * next_value * (1 - dones)critic_1_loss = torch.mean(F.mse_loss(self.critic_1(states, actions), td_target.detach()))critic_2_loss = torch.mean(F.mse_loss(self.critic_2(states, actions), td_target.detach()))# 以上与SAC相同,以下Q网络更新是CQL的额外部分batch_size = states.shape[0]random_unif_actions = torch.rand([batch_size * self.num_random, actions.shape[-1]],dtype=torch.float).uniform_(-1, 1).to(device)random_unif_log_pi = np.log(0.5**next_actions.shape[-1])tmp_states = states.unsqueeze(1).repeat(1, self.num_random,1).view(-1, states.shape[-1])tmp_next_states = next_states.unsqueeze(1).repeat(1, self.num_random, 1).view(-1, next_states.shape[-1])random_curr_actions, random_curr_log_pi = self.actor(tmp_states)random_next_actions, random_next_log_pi = self.actor(tmp_next_states)q1_unif = self.critic_1(tmp_states, random_unif_actions).view(-1, self.num_random, 1)q2_unif = self.critic_2(tmp_states, random_unif_actions).view(-1, self.num_random, 1)q1_curr = self.critic_1(tmp_states, random_curr_actions).view(-1, self.num_random, 1)q2_curr = self.critic_2(tmp_states, random_curr_actions).view(-1, self.num_random, 1)q1_next = self.critic_1(tmp_states, random_next_actions).view(-1, self.num_random, 1)q2_next = self.critic_2(tmp_states, random_next_actions).view(-1, self.num_random, 1)q1_cat = torch.cat([q1_unif - random_unif_log_pi,q1_curr - random_curr_log_pi.detach().view(-1, self.num_random, 1),q1_next - random_next_log_pi.detach().view(-1, self.num_random, 1)],dim=1)q2_cat = torch.cat([q2_unif - random_unif_log_pi,q2_curr - random_curr_log_pi.detach().view(-1, self.num_random, 1),q2_next - random_next_log_pi.detach().view(-1, self.num_random, 1)],dim=1)qf1_loss_1 = torch.logsumexp(q1_cat, dim=1).mean()qf2_loss_1 = torch.logsumexp(q2_cat, dim=1).mean()qf1_loss_2 = self.critic_1(states, actions).mean()qf2_loss_2 = self.critic_2(states, actions).mean()qf1_loss = critic_1_loss + self.beta * (qf1_loss_1 - qf1_loss_2)qf2_loss = critic_2_loss + self.beta * (qf2_loss_1 - qf2_loss_2)self.critic_1_optimizer.zero_grad()qf1_loss.backward(retain_graph=True)self.critic_1_optimizer.step()self.critic_2_optimizer.zero_grad()qf2_loss.backward(retain_graph=True)self.critic_2_optimizer.step()# 更新策略网络new_actions, log_prob = self.actor(states)entropy = -log_probq1_value = self.critic_1(states, new_actions)q2_value = self.critic_2(states, new_actions)actor_loss = torch.mean(-self.log_alpha.exp() * entropy -torch.min(q1_value, q2_value))self.actor_optimizer.zero_grad()actor_loss.backward()self.actor_optimizer.step()# 更新alpha值alpha_loss = torch.mean((entropy - self.target_entropy).detach() * self.log_alpha.exp())self.log_alpha_optimizer.zero_grad()alpha_loss.backward()self.log_alpha_optimizer.step()self.soft_update(self.critic_1, self.target_critic_1)self.soft_update(self.critic_2, self.target_critic_2)
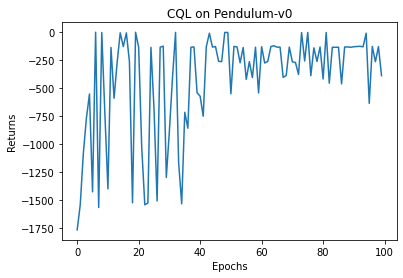
接下来设置好超参数,就可以开始训练了。最后再绘图看一下算法的表现。因为不能通过与环境交互来获得新的数据,离线算法最终的效果和数据集有很大关系,并且波动会比较大。通常来说,调参后数据集中的样本质量越高,算法的表现就越好。感兴趣的读者可以使用其他方式生成数据集,并观察算法效果的变化。
random.seed(0)np.random.seed(0)env.seed(0)torch.manual_seed(0)beta = 5.0num_random = 5num_epochs = 100num_trains_per_epoch = 500agent = CQL(state_dim, hidden_dim, action_dim, action_bound, actor_lr,critic_lr, alpha_lr, target_entropy, tau, gamma, device, beta,num_random)return_list = []for i in range(10):with tqdm(total=int(num_epochs / 10), desc='Iteration %d' % i) as pbar:for i_epoch in range(int(num_epochs / 10)):# 此处与环境交互只是为了评估策略,最后作图用,不会用于训练epoch_return = 0state = env.reset()done = Falsewhile not done:action = agent.take_action(state)next_state, reward, done, _ = env.step(action)state = next_stateepoch_return += rewardreturn_list.append(epoch_return)for _ in range(num_trains_per_epoch):b_s, b_a, b_r, b_ns, b_d = replay_buffer.sample(batch_size)transition_dict = {'states': b_s,'actions': b_a,'next_states': b_ns,'rewards': b_r,'dones': b_d}agent.update(transition_dict)if (i_epoch + 1) % 10 == 0:pbar.set_postfix({'epoch':'%d' % (num_epochs / 10 * i + i_epoch + 1),'return':'%.3f' % np.mean(return_list[-10:])})pbar.update(1)
Iteration 0: 100%|██████████| 10/10 [01:26<00:00, 8.62s/it, epoch=10, return=-941.721]Iteration 1: 100%|██████████| 10/10 [01:27<00:00, 8.72s/it, epoch=20, return=-432.056]Iteration 2: 100%|██████████| 10/10 [01:26<00:00, 8.68s/it, epoch=30, return=-810.899]Iteration 3: 100%|██████████| 10/10 [01:27<00:00, 8.70s/it, epoch=40, return=-636.281]Iteration 4: 100%|██████████| 10/10 [01:26<00:00, 8.64s/it, epoch=50, return=-224.978]Iteration 5: 100%|██████████| 10/10 [01:27<00:00, 8.79s/it, epoch=60, return=-298.303]Iteration 6: 100%|██████████| 10/10 [01:30<00:00, 9.05s/it, epoch=70, return=-210.535]Iteration 7: 100%|██████████| 10/10 [01:29<00:00, 8.99s/it, epoch=80, return=-209.631]Iteration 8: 100%|██████████| 10/10 [01:29<00:00, 8.98s/it, epoch=90, return=-213.836]Iteration 9: 100%|██████████| 10/10 [01:33<00:00, 9.36s/it, epoch=100, return=-206.435]
epochs_list = list(range(len(return_list)))plt.plot(epochs_list, return_list)plt.xlabel('Epochs')plt.ylabel('Returns')plt.title('CQL on {}'.format(env_name))plt.show()mv_return = rl_utils.moving_average(return_list, 9)plt.plot(episodes_list, mv_return)plt.xlabel('Episodes')plt.ylabel('Returns')plt.title('CQL on {}'.format(env_name))plt.show()
18.5 总结
本章介绍了离线强化学习的基本概念和两个与模型无关的离线强化学习算法——BCQ 和 CQL,并讲解了 CQL 的代码。事实上,离线强化学习还有一类基于模型的方法,如 model-based offline reinforcement learning (MOReL)和 model-based offline policy optimization(MOPO),本章由于篇幅原因不再介绍。这一类算法的思路基本是通过模型生成更多数据,同时通过衡量模型预测的不确定性来对生成的偏离数据集的数据进行惩罚,感兴趣的读者可以自行查阅相关资料。
离线强化学习的另一大难点是算法通常对超参数极为敏感,非常难调参。并且在实际复杂场景中通常不能像在模拟器中那样,每训练几轮就在环境中评估策略好坏,如何确定何时停止算法也是离线强化学习在实际应用中面临的一大挑战。此外,离线强化学习在现实场景中的落地还需要关注离散策略评估和选择、数据收集策略的保守性和数据缺失性等现实问题。不过无论如何,离线强化学习和模仿学习都是为了解决在现实中训练智能体的困难而提出的,也都是强化学习真正落地的重要途径。
18.6 扩展阅读
这里对 CQL 算法中
把 KL 散度展开,由于
回到 18.3 节,可以发现,在原迭代方程中,含有
这一问题的求解要用到变分法。对于等式约束和不等式约束,引入拉格朗日乘数
其中,
写出欧拉-拉格朗日方程
由于第二项
两项的乘积等于零,因此在每一点上,要么
最终的解
其中,
对照原迭代方程,将
此处的期望是对
至此,式中已经不含
18.7 参考文献
[1] LEVINE S, KUMAR A, TUCKER. G, et al. Offline reinforcement learning: tutorial, review, and perspectives on open problems [J]. 2020.
[2] FUJIMOTO S, MEGER D, PRECUP D. Off-policy deep reinforcement learning without exploration [C] // International conference on machine learning, PMLR, 2019.
[3] KINGMA D P, WELLING M. Auto-encoding variational bayes [C] // International conference on learning representations, ICLR, 2014.
[4] KUMAR A, ZHOU A, TUCKER G, et al. Conservative q-learning for offline reinforcement learning [J]. NeurIPS, 2020.
[5] KIDAMBL R, RAJESWARAN A, NETRAPALLI P, et al. MOReL: Model-based offline reinforcement learning [J]. Advances in neural information processing systems, 2020: 33.
[6] YU T, THOMAS G, YU L, et al. MOPO: Model-based offline policy optimization [J]. Advances in neural information processing systems, 2020: 33.