第 19 章 目标导向的强化学习
19.1 简介
前文已经学习了 PPO、SAC 等经典的深度强化学习算法,大部分算法都能在各自的任务中取得比较好的效果,但是它们都局限在单个任务上,换句话说,对于训练完的算法,在使用时它们都只能完成一个特定的任务。如果面对较为复杂的复合任务,之前的强化学习算法往往不容易训练出有效的策略。本章将介绍目标导向的强化学习(goal-oriented reinforcement learning,GoRL)以及该类别下的一种经典算法 HER。GoRL 可以学习一个策略,使其可以在不同的目标(goal)作为条件下奏效,以此来解决较为复杂的决策任务。
19.2 问题定义
在介绍概念之前,先介绍一个目标导向的强化学习的实际场景。例如,策略
接下来讨论 GoRL 的数学形式。有别于一般的强化学习算法中定义的马尔可夫决策过程,在目标导向的强化学习中,使用一个扩充过的元组
首先是补充的目标空间
然后介绍奖励函数,奖励函数不仅与状态
其中,
19.3 HER 算法
根据 19.2 节的定义,可以发现目标导向的强化学习的奖励往往是非常稀疏的。由于智能体在训练初期难以完成目标而只能得到
假设现在使用策略
下面来看看具体的算法流程。值得注意的是,这里的策略优化算法可以选择任意合适的算法,比如 DQN、DDPG 等。
- 初始化策略
的参数 ,初始化经验回放池 - For 序列
根据环境给予的目标 和初始状态 ,使用 在环境中采样得到轨迹 ,将其以 的形式存入 中 从 中采样 个 元组 对于这些元组,选择一个状态 ,将其映射为新的目标 并计算新的奖励值 ,然后用新的数据 替换原先的元组 使用这些新元组,对策略 进行训练 - End for
对于算法中状态
- future: 选择与被改写的元组
处于同一个轨迹并在时间上处于 之后的某个状态作为 。 - episode: 选择与被改写的元组
处于同一个轨迹的某个状态作为 。 - random: 选择经验回放池中的某个状态作为
。
在 HER 的实验中,future 方案给出了最好的效果,该方案也最直观。因此在代码实现中用的是 future 方案。
19.4 HER 代码实践
接下来看看如何实现 HER 算法。首先定义一个简单二维平面上的环境。在一个二维网格世界上,每个维度的位置范围是
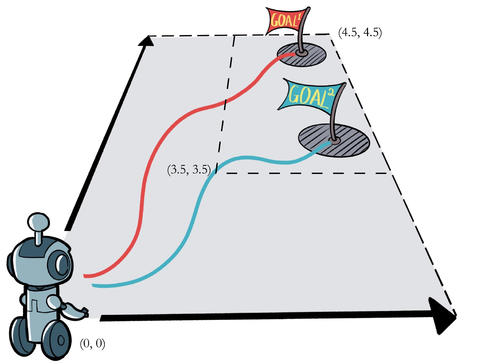
使用 Python 实现这个环境。导入一些需要用到的包,并且用代码来定义该环境。
import torchimport torch.nn.functional as Fimport numpy as npimport randomfrom tqdm import tqdmimport collectionsimport matplotlib.pyplot as pltclass WorldEnv:def __init__(self):self.distance_threshold = 0.15self.action_bound = 1def reset(self): # 重置环境# 生成一个目标状态, 坐标范围是[3.5~4.5, 3.5~4.5]self.goal = np.array([4 + random.uniform(-0.5, 0.5), 4 + random.uniform(-0.5, 0.5)])self.state = np.array([0, 0]) # 初始状态self.count = 0return np.hstack((self.state, self.goal))def step(self, action):action = np.clip(action, -self.action_bound, self.action_bound)x = max(0, min(5, self.state[0] + action[0]))y = max(0, min(5, self.state[1] + action[1]))self.state = np.array([x, y])self.count += 1dis = np.sqrt(np.sum(np.square(self.state - self.goal)))reward = -1.0 if dis > self.distance_threshold else 0if dis <= self.distance_threshold or self.count == 50:done = Trueelse:done = Falsereturn np.hstack((self.state, self.goal)), reward, done
接下来实现 DDPG 算法中用到的与 Actor 网络和 Critic 网络的网络结构相关的代码。
class PolicyNet(torch.nn.Module):def __init__(self, state_dim, hidden_dim, action_dim, action_bound):super(PolicyNet, self).__init__()self.fc1 = torch.nn.Linear(state_dim, hidden_dim)self.fc2 = torch.nn.Linear(hidden_dim, hidden_dim)self.fc3 = torch.nn.Linear(hidden_dim, action_dim)self.action_bound = action_bound # action_bound是环境可以接受的动作最大值def forward(self, x):x = F.relu(self.fc2(F.relu(self.fc1(x))))return torch.tanh(self.fc3(x)) * self.action_boundclass QValueNet(torch.nn.Module):def __init__(self, state_dim, hidden_dim, action_dim):super(QValueNet, self).__init__()self.fc1 = torch.nn.Linear(state_dim + action_dim, hidden_dim)self.fc2 = torch.nn.Linear(hidden_dim, hidden_dim)self.fc3 = torch.nn.Linear(hidden_dim, 1)def forward(self, x, a):cat = torch.cat([x, a], dim=1) # 拼接状态和动作x = F.relu(self.fc2(F.relu(self.fc1(cat))))return self.fc3(x)
在定义好 Actor 和 Critic 的网络结构之后,来看一下 DDPG 算法的代码。这部分代码和 13.3 节中的代码基本一致,主要区别在于 13.3 节中的 DDPG 算法是在倒立摆环境中运行的,动作只有 1 维,而这里的环境中动作有 2 维,导致一小部分代码不同。读者可以先思考一下此时应该修改哪一部分代码,然后自行对比,就能找到不同之处。
class DDPG:''' DDPG算法 '''def __init__(self, state_dim, hidden_dim, action_dim, action_bound,actor_lr, critic_lr, sigma, tau, gamma, device):self.action_dim = action_dimself.actor = PolicyNet(state_dim, hidden_dim, action_dim,action_bound).to(device)self.critic = QValueNet(state_dim, hidden_dim, action_dim).to(device)self.target_actor = PolicyNet(state_dim, hidden_dim, action_dim,action_bound).to(device)self.target_critic = QValueNet(state_dim, hidden_dim,action_dim).to(device)# 初始化目标价值网络并使其参数和价值网络一样self.target_critic.load_state_dict(self.critic.state_dict())# 初始化目标策略网络并使其参数和策略网络一样self.target_actor.load_state_dict(self.actor.state_dict())self.actor_optimizer = torch.optim.Adam(self.actor.parameters(),lr=actor_lr)self.critic_optimizer = torch.optim.Adam(self.critic.parameters(),lr=critic_lr)self.gamma = gammaself.sigma = sigma # 高斯噪声的标准差,均值直接设为0self.tau = tau # 目标网络软更新参数self.action_bound = action_boundself.device = devicedef take_action(self, state):state = torch.tensor([state], dtype=torch.float).to(self.device)action = self.actor(state).detach().cpu().numpy()[0]# 给动作添加噪声,增加探索action = action + self.sigma * np.random.randn(self.action_dim)return actiondef soft_update(self, net, target_net):for param_target, param in zip(target_net.parameters(),net.parameters()):param_target.data.copy_(param_target.data * (1.0 - self.tau) +param.data * self.tau)def update(self, transition_dict):states = torch.tensor(transition_dict['states'],dtype=torch.float).to(self.device)actions = torch.tensor(transition_dict['actions'],dtype=torch.float).to(self.device)rewards = torch.tensor(transition_dict['rewards'],dtype=torch.float).view(-1, 1).to(self.device)next_states = torch.tensor(transition_dict['next_states'],dtype=torch.float).to(self.device)dones = torch.tensor(transition_dict['dones'],dtype=torch.float).view(-1, 1).to(self.device)next_q_values = self.target_critic(next_states,self.target_actor(next_states))q_targets = rewards + self.gamma * next_q_values * (1 - dones)# MSE损失函数critic_loss = torch.mean(F.mse_loss(self.critic(states, actions), q_targets))self.critic_optimizer.zero_grad()critic_loss.backward()self.critic_optimizer.step()# 策略网络就是为了使Q值最大化actor_loss = -torch.mean(self.critic(states, self.actor(states)))self.actor_optimizer.zero_grad()actor_loss.backward()self.actor_optimizer.step()self.soft_update(self.actor, self.target_actor) # 软更新策略网络self.soft_update(self.critic, self.target_critic) # 软更新价值网络
接下来定义一个特殊的经验回放池,此时回放池内不再存储每一步的数据,而是存储一整条轨迹。这是 HER 算法中的核心部分,之后可以用 HER 算法从该经验回放池中构建新的数据来帮助策略训练。
class Trajectory:''' 用来记录一条完整轨迹 '''def __init__(self, init_state):self.states = [init_state]self.actions = []self.rewards = []self.dones = []self.length = 0def store_step(self, action, state, reward, done):self.actions.append(action)self.states.append(state)self.rewards.append(reward)self.dones.append(done)self.length += 1class ReplayBuffer_Trajectory:''' 存储轨迹的经验回放池 '''def __init__(self, capacity):self.buffer = collections.deque(maxlen=capacity)def add_trajectory(self, trajectory):self.buffer.append(trajectory)def size(self):return len(self.buffer)def sample(self, batch_size, use_her, dis_threshold=0.15, her_ratio=0.8):batch = dict(states=[],actions=[],next_states=[],rewards=[],dones=[])for _ in range(batch_size):traj = random.sample(self.buffer, 1)[0]step_state = np.random.randint(traj.length)state = traj.states[step_state]next_state = traj.states[step_state + 1]action = traj.actions[step_state]reward = traj.rewards[step_state]done = traj.dones[step_state]if use_her and np.random.uniform() <= her_ratio:step_goal = np.random.randint(step_state + 1, traj.length + 1)goal = traj.states[step_goal][:2] # 使用HER算法的future方案设置目标dis = np.sqrt(np.sum(np.square(next_state[:2] - goal)))reward = -1.0 if dis > dis_threshold else 0done = False if dis > dis_threshold else Truestate = np.hstack((state[:2], goal))next_state = np.hstack((next_state[:2], goal))batch['states'].append(state)batch['next_states'].append(next_state)batch['actions'].append(action)batch['rewards'].append(reward)batch['dones'].append(done)batch['states'] = np.array(batch['states'])batch['next_states'] = np.array(batch['next_states'])batch['actions'] = np.array(batch['actions'])return batch
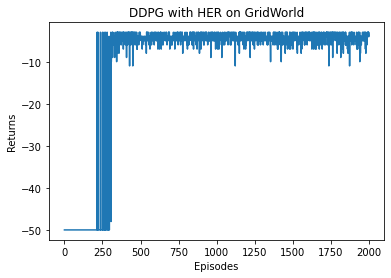
最后,便可以开始在这个有目标的环境中运行采用了 HER 的 DDPG 算法,一起来看一下效果吧。
actor_lr = 1e-3critic_lr = 1e-3hidden_dim = 128state_dim = 4action_dim = 2action_bound = 1sigma = 0.1tau = 0.005gamma = 0.98num_episodes = 2000n_train = 20batch_size = 256minimal_episodes = 200buffer_size = 10000device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")random.seed(0)np.random.seed(0)torch.manual_seed(0)env = WorldEnv()replay_buffer = ReplayBuffer_Trajectory(buffer_size)agent = DDPG(state_dim, hidden_dim, action_dim, action_bound, actor_lr,critic_lr, sigma, tau, gamma, device)return_list = []for i in range(10):with tqdm(total=int(num_episodes / 10), desc='Iteration %d' % i) as pbar:for i_episode in range(int(num_episodes / 10)):episode_return = 0state = env.reset()traj = Trajectory(state)done = Falsewhile not done:action = agent.take_action(state)state, reward, done = env.step(action)episode_return += rewardtraj.store_step(action, state, reward, done)replay_buffer.add_trajectory(traj)return_list.append(episode_return)if replay_buffer.size() >= minimal_episodes:for _ in range(n_train):transition_dict = replay_buffer.sample(batch_size, True)agent.update(transition_dict)if (i_episode + 1) % 10 == 0:pbar.set_postfix({'episode':'%d' % (num_episodes / 10 * i + i_episode + 1),'return':'%.3f' % np.mean(return_list[-10:])})pbar.update(1)episodes_list = list(range(len(return_list)))plt.plot(episodes_list, return_list)plt.xlabel('Episodes')plt.ylabel('Returns')plt.title('DDPG with HER on {}'.format('GridWorld'))plt.show()
Iteration 0: 0%| | 0/200 [00:00<?, ?it/s]/usr/local/lib/python3.7/dist-packages/ipykernel_launcher.py:23: UserWarning: Creating a tensor from a list of numpy.ndarrays is extremely slow. Please consider converting the list to a single numpy.ndarray with numpy.array() before converting to a tensor. (Triggered internally at ../torch/csrc/utils/tensor_new.cpp:201.)Iteration 0: 100%|██████████| 200/200 [00:08<00:00, 24.96it/s, episode=200, return=-50.000]Iteration 1: 100%|██████████| 200/200 [01:41<00:00, 1.96it/s, episode=400, return=-4.400]Iteration 2: 100%|██████████| 200/200 [01:37<00:00, 2.06it/s, episode=600, return=-4.000]Iteration 3: 100%|██████████| 200/200 [01:36<00:00, 2.07it/s, episode=800, return=-4.100]Iteration 4: 100%|██████████| 200/200 [01:35<00:00, 2.09it/s, episode=1000, return=-4.500]Iteration 5: 100%|██████████| 200/200 [01:34<00:00, 2.11it/s, episode=1200, return=-4.500]Iteration 6: 100%|██████████| 200/200 [01:36<00:00, 2.08it/s, episode=1400, return=-4.600]Iteration 7: 100%|██████████| 200/200 [01:35<00:00, 2.09it/s, episode=1600, return=-4.100]Iteration 8: 100%|██████████| 200/200 [01:35<00:00, 2.09it/s, episode=1800, return=-4.300]Iteration 9: 100%|██████████| 200/200 [01:35<00:00, 2.09it/s, episode=2000, return=-3.600]
接下来尝试不采用 HER 重新构造数据,而是直接使用收集的数据训练一个策略,看看是什么效果。
random.seed(0)np.random.seed(0)torch.manual_seed(0)env = WorldEnv()replay_buffer = ReplayBuffer_Trajectory(buffer_size)agent = DDPG(state_dim, hidden_dim, action_dim, action_bound, actor_lr,critic_lr, sigma, tau, gamma, device)return_list = []for i in range(10):with tqdm(total=int(num_episodes / 10), desc='Iteration %d' % i) as pbar:for i_episode in range(int(num_episodes / 10)):episode_return = 0state = env.reset()traj = Trajectory(state)done = Falsewhile not done:action = agent.take_action(state)state, reward, done = env.step(action)episode_return += rewardtraj.store_step(action, state, reward, done)replay_buffer.add_trajectory(traj)return_list.append(episode_return)if replay_buffer.size() >= minimal_episodes:for _ in range(n_train):# 和使用HER训练的唯一区别transition_dict = replay_buffer.sample(batch_size, False)agent.update(transition_dict)if (i_episode + 1) % 10 == 0:pbar.set_postfix({'episode':'%d' % (num_episodes / 10 * i + i_episode + 1),'return':'%.3f' % np.mean(return_list[-10:])})pbar.update(1)episodes_list = list(range(len(return_list)))plt.plot(episodes_list, return_list)plt.xlabel('Episodes')plt.ylabel('Returns')plt.title('DDPG without HER on {}'.format('GridWorld'))plt.show()
Iteration 0: 100%|██████████| 200/200 [00:03<00:00, 65.09it/s, episode=200, return=-50.000]Iteration 1: 100%|██████████| 200/200 [00:45<00:00, 4.42it/s, episode=400, return=-50.000]Iteration 2: 100%|██████████| 200/200 [00:46<00:00, 4.28it/s, episode=600, return=-50.000]Iteration 3: 100%|██████████| 200/200 [00:48<00:00, 4.14it/s, episode=800, return=-50.000]Iteration 4: 100%|██████████| 200/200 [00:47<00:00, 4.24it/s, episode=1000, return=-50.000]Iteration 5: 100%|██████████| 200/200 [00:46<00:00, 4.28it/s, episode=1200, return=-50.000]Iteration 6: 100%|██████████| 200/200 [00:46<00:00, 4.27it/s, episode=1400, return=-50.000]Iteration 7: 100%|██████████| 200/200 [00:48<00:00, 4.14it/s, episode=1600, return=-40.600]Iteration 8: 100%|██████████| 200/200 [00:47<00:00, 4.18it/s, episode=1800, return=-50.000]Iteration 9: 100%|██████████| 200/200 [00:50<00:00, 3.99it/s, episode=2000, return=-31.500]

通过实验对比,可以观察到使用 HER 算法后,效果有显著提升。这里 HER 算法的主要好处是通过重新对历史轨迹设置其目标(使用 future 方案)而使得奖励信号更加稠密,进而从原本失败的数据中学习到使“新任务”成功的经验,提升训练的稳定性和样本效率。
19.5 小结
本章介绍了目标导向的强化学习(GoRL)的基本定义,以及一个解决 GoRL 的有效的经典算法 HER。通过代码实践,HER 算法的效果得到了很好的呈现。我们从 HER 的代码实践中还可以领会一种思维方式,即可以通过整条轨迹的信息来改善每个转移片段带给智能体策略的学习价值。例如,在 HER 算法的 future 方案中,采样当前轨迹后续的状态作为目标,然后根据下一步状态是否离目标足够近来修改当前步的奖励信号。此外,HER 算法只是一个经验回放的修改方式,并没有对策略网络和价值网络的架构做出任何修改。而在后续的部分 GoRL 研究中,策略函数和动作价值函数会被显式建模成
19.6 参考文献
[1] ANDRYCHOWICZ M, WOLSKI F, RAY A, et al. Hindsight Experience Replay [J]. Advances in neural information processing systems, 2017: 5055-5065.
[2] FLORENSA C, HELD D, GENG X Y, et al. Automatic goal generation for reinforcement learning agents [C]// International conference on machine learning, PMLR, 2018: 1515-1528.
[3] REN Z Z, DONG K, ZHOU Y, et al. Exploration via Hindsight Goal Generation [J]. Advances in neural information processing systems 2019, 32: 13485-13496.
[4] PITIS S, CHAN H, ZHAO S, et al. Maximum entropy gain exploration for long horizon multi-goal reinforcement learning [C]// International conference on machine learning, PMLR, 2020: 7750-7761.