第 10 章 Actor-Critic 算法
10.1 简介
本书之前的章节讲解了基于值函数的方法(DQN)和基于策略的方法(REINFORCE),其中基于值函数的方法只学习一个价值函数,而基于策略的方法只学习一个策略函数。那么,一个很自然的问题是,有没有什么方法既学习价值函数,又学习策略函数呢?答案就是 Actor-Critic。Actor-Critic 是囊括一系列算法的整体架构,目前很多高效的前沿算法都属于 Actor-Critic 算法,本章接下来将会介绍一种最简单的 Actor-Critic 算法。需要明确的是,Actor-Critic 算法本质上是基于策略的算法,因为这一系列算法的目标都是优化一个带参数的策略,只是会额外学习价值函数,从而帮助策略函数更好地学习。
10.2 Actor-Critic
回顾一下,在 REINFORCE 算法中,目标函数的梯度中有一项轨迹回报,用于指导策略的更新。REINFOCE 算法用蒙特卡洛方法来估计
其中,
9.5 节提到 REINFORCE 通过蒙特卡洛采样的方法对策略梯度的估计是无偏的,但是方差非常大。我们可以用形式(3)引入基线函数(baseline function)
本章将着重介绍形式(6),即通过时序差分残差
我们将 Actor-Critic 分为两个部分:Actor(策略网络)和 Critic(价值网络),如图 10-1 所示。
- Actor 要做的是与环境交互,并在 Critic 价值函数的指导下用策略梯度学习一个更好的策略。
- Critic 要做的是通过 Actor 与环境交互收集的数据学习一个价值函数,这个价值函数会用于判断在当前状态什么动作是好的,什么动作不是好的,进而帮助 Actor 进行策略更新。

Actor 的更新采用策略梯度的原则,那 Critic 如何更新呢?我们将 Critic 价值网络表示为
与 DQN 中一样,我们采取类似于目标网络的方法,将上式中
然后使用梯度下降方法来更新 Critic 价值网络参数即可。
Actor-Critic 算法的具体流程如下:
- 初始化策略网络参数
,价值网络参数 - for 序列
do : 用当前策略 采样轨迹 为每一步数据计算: 更新价值参数 更新策略参数 - end for
以上就是 Actor-Critic 算法的流程,接下来让我们来用代码实现它,看看效果如何吧!
10.3 Actor-Critic 代码实践
我们仍然在车杆环境上进行 Actor-Critic 算法的实验。
import gymimport torchimport torch.nn.functional as Fimport numpy as npimport matplotlib.pyplot as pltimport rl_utils
首先定义策略网络PolicyNet(与 REINFORCE 算法一样)。
class PolicyNet(torch.nn.Module):def __init__(self, state_dim, hidden_dim, action_dim):super(PolicyNet, self).__init__()self.fc1 = torch.nn.Linear(state_dim, hidden_dim)self.fc2 = torch.nn.Linear(hidden_dim, action_dim)def forward(self, x):x = F.relu(self.fc1(x))return F.softmax(self.fc2(x), dim=1)
Actor-Critic 算法中额外引入一个价值网络,接下来的代码定义价值网络ValueNet,其输入是某个状态,输出则是状态的价值。
class ValueNet(torch.nn.Module):def __init__(self, state_dim, hidden_dim):super(ValueNet, self).__init__()self.fc1 = torch.nn.Linear(state_dim, hidden_dim)self.fc2 = torch.nn.Linear(hidden_dim, 1)def forward(self, x):x = F.relu(self.fc1(x))return self.fc2(x)
现在定义ActorCritic算法,主要包含采取动作(take_action())和更新网络参数(update())两个函数。
class ActorCritic:def __init__(self, state_dim, hidden_dim, action_dim, actor_lr, critic_lr,gamma, device):# 策略网络self.actor = PolicyNet(state_dim, hidden_dim, action_dim).to(device)self.critic = ValueNet(state_dim, hidden_dim).to(device) # 价值网络# 策略网络优化器self.actor_optimizer = torch.optim.Adam(self.actor.parameters(),lr=actor_lr)self.critic_optimizer = torch.optim.Adam(self.critic.parameters(),lr=critic_lr) # 价值网络优化器self.gamma = gammaself.device = devicedef take_action(self, state):state = torch.tensor([state], dtype=torch.float).to(self.device)probs = self.actor(state)action_dist = torch.distributions.Categorical(probs)action = action_dist.sample()return action.item()def update(self, transition_dict):states = torch.tensor(transition_dict['states'],dtype=torch.float).to(self.device)actions = torch.tensor(transition_dict['actions']).view(-1, 1).to(self.device)rewards = torch.tensor(transition_dict['rewards'],dtype=torch.float).view(-1, 1).to(self.device)next_states = torch.tensor(transition_dict['next_states'],dtype=torch.float).to(self.device)dones = torch.tensor(transition_dict['dones'],dtype=torch.float).view(-1, 1).to(self.device)# 时序差分目标td_target = rewards + self.gamma * self.critic(next_states) * (1 -dones)td_delta = td_target - self.critic(states) # 时序差分误差log_probs = torch.log(self.actor(states).gather(1, actions))actor_loss = torch.mean(-log_probs * td_delta.detach())# 均方误差损失函数critic_loss = torch.mean(F.mse_loss(self.critic(states), td_target.detach()))self.actor_optimizer.zero_grad()self.critic_optimizer.zero_grad()actor_loss.backward() # 计算策略网络的梯度critic_loss.backward() # 计算价值网络的梯度self.actor_optimizer.step() # 更新策略网络的参数self.critic_optimizer.step() # 更新价值网络的参数
定义好 Actor 和 Critic,我们就可以开始实验了,看看 Actor-Critic 在车杆环境上表现如何吧!
actor_lr = 1e-3critic_lr = 1e-2num_episodes = 1000hidden_dim = 128gamma = 0.98device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")env_name = 'CartPole-v0'env = gym.make(env_name)env.seed(0)torch.manual_seed(0)state_dim = env.observation_space.shape[0]action_dim = env.action_space.nagent = ActorCritic(state_dim, hidden_dim, action_dim, actor_lr, critic_lr,gamma, device)return_list = rl_utils.train_on_policy_agent(env, agent, num_episodes)
Iteration 0: 0%| | 0/100 [00:00<?, ?it/s]/usr/local/lib/python3.7/dist-packages/ipykernel_launcher.py:15: UserWarning: Creating a tensor from a list of numpy.ndarrays is extremely slow. Please consider converting the list to a single numpy.ndarray with numpy.array() before converting to a tensor. (Triggered internally at ../torch/csrc/utils/tensor_new.cpp:201.)from ipykernel import kernelapp as appIteration 0: 100%|██████████| 100/100 [00:00<00:00, 101.75it/s, episode=100, return=21.100]Iteration 1: 100%|██████████| 100/100 [00:01<00:00, 58.71it/s, episode=200, return=72.800]Iteration 2: 100%|██████████| 100/100 [00:05<00:00, 19.73it/s, episode=300, return=109.300]Iteration 3: 100%|██████████| 100/100 [00:05<00:00, 17.30it/s, episode=400, return=163.000]Iteration 4: 100%|██████████| 100/100 [00:06<00:00, 16.27it/s, episode=500, return=193.600]Iteration 5: 100%|██████████| 100/100 [00:06<00:00, 15.90it/s, episode=600, return=195.900]Iteration 6: 100%|██████████| 100/100 [00:06<00:00, 15.80it/s, episode=700, return=199.100]Iteration 7: 100%|██████████| 100/100 [00:06<00:00, 15.72it/s, episode=800, return=186.900]Iteration 8: 100%|██████████| 100/100 [00:06<00:00, 15.94it/s, episode=900, return=200.000]Iteration 9: 100%|██████████| 100/100 [00:06<00:00, 15.45it/s, episode=1000, return=200.000]
在 CartPole-v0 环境中,满分就是 200 分。和 REINFORCE 相似,接下来我们绘制训练过程中每一条轨迹的回报变化图以及其经过平滑处理的版本。
episodes_list = list(range(len(return_list)))plt.plot(episodes_list, return_list)plt.xlabel('Episodes')plt.ylabel('Returns')plt.title('Actor-Critic on {}'.format(env_name))plt.show()mv_return = rl_utils.moving_average(return_list, 9)plt.plot(episodes_list, mv_return)plt.xlabel('Episodes')plt.ylabel('Returns')plt.title('Actor-Critic on {}'.format(env_name))plt.show()
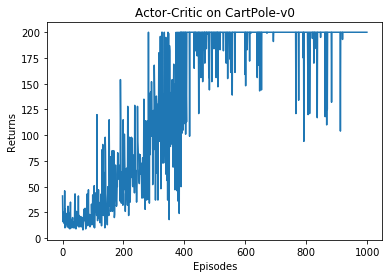
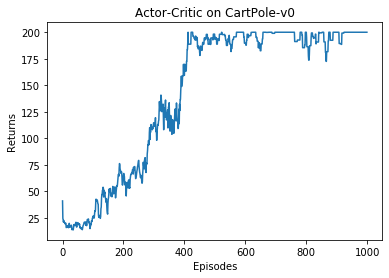
根据实验结果我们可以发现,Actor-Critic 算法很快便能收敛到最优策略,并且训练过程非常稳定,抖动情况相比 REINFORCE 算法有了明显的改进,这说明价值函数的引入减小了方差。
10.4 总结
本章讲解了 Actor-Critic 算法,它是基于值函数的方法和基于策略的方法的叠加。价值模块 Critic 在策略模块 Actor 采样的数据中学习分辨什么是好的动作,什么不是好的动作,进而指导 Actor 进行策略更新。随着 Actor 的训练的进行,其与环境交互所产生的数据分布也发生改变,这需要 Critic 尽快适应新的数据分布并给出好的判别。
Actor-Critic 算法非常实用,后续章节中的 TRPO、PPO、DDPG、SAC 等深度强化学习算法都是在 Actor-Critic 框架下进行发展的。深入了解 Actor-Critic 算法对读懂目前深度强化学习的研究热点大有裨益。
10.5 参考文献
[1] KONDA, V R, TSITSIKLIS J N. Actor-critic algorithms [C]// Advances in neural information processing systems, 2000.